-
[+Code] pd.melt 정복하기python/Pandas 2020. 10. 24. 04:03
데이터프레임을 생성합니다.
df = pd.DataFrame(data = {"Month":["1월","2월","3월","4월","5월", "6월","7월","8월","9월","10월"], "부산":np.random.randint(10, size=(1,10)).tolist()[0], "서울":np.random.randint(20,size=(1,10)).tolist()[0], "광주":np.random.randint(30,size=(1,10)).tolist()[0]}) df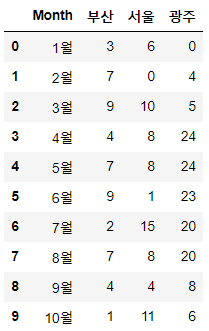
월별 교통사고 건수에 대한 데이터셋을 임의로 만들었습니다. 만약 컬럼이 대한민국 시별로 구성되어 있고, 지역별 교통사고 건수의 평균을 알아보고 싶으면 어떻게 해야 할까요? 가능은 하겠지만 귀찮습니다. 보통 자주 사용하는 groupby함수도 사용할 수가 없죠. 이런 경우에 melt를 활용할 수 있습니다. 쉽게 말하면 column을 녹여서 데이터프레임 안으로 집어넣는다고 생각하시면 될 것 같습니다.
# id_vars = 기준이 될 컬럼명 # value_vars = 녹여서 데이터프레임 안으로 집어넣을 컬럼명 melted = df.melt(id_vars=["Month"], value_vars=["부산","서울","광주"]) melted
부산 서울 광주의 컬럼이 범주형 데이터처럼 바뀐 것을 알 수 있습니다. 이러면 우리가 구하려고 하면 지역별 평균을 알기 쉽겠죠.
melted.groupby(by="variable")["value"].mean().reset_index()
melt시에 발생하는 variable과 value 컬럼명은 melt의 파라미터로 조정할 수 있습니다. var_name과 value_name에 지정하고 싶은 name을 입력하면
melted = df.melt(id_vars=["Month"], value_vars=["부산","서울","광주"], var_name="지역",value_name="건수") melted
위와 같이 되는 것을 확인할 수 있습니다. 또한 이렇게 melt를 하게 되면 시각화도 굉장히 편리해집니다. 단 코드 한 줄로 월별, 지역별 교통사고 추이를 확인할 수 있습니다.
import plotly_express as px px.line(data_frame=melted, x="Month", y="건수", color="지역")
'python > Pandas' 카테고리의 다른 글
[+Code] concat, merge 정복하기 (0) 2020.10.24 DataFrame Value에 리스트가 들어가 있을 때 DataFrame을 저장하면 문자열로 바뀌는 문제 (0) 2020.09.04