-
[+Code]KFold, Stratified, Repeated, Group의 차이점python/scikit-learn 2020. 10. 23. 12:14
참조 : towardsdatascience.com/how-to-train-test-split-kfold-vs-stratifiedkfold-281767b93869
How to train_test_split : KFold vs StratifiedKFold
Explained with examples
towardsdatascience.com
여러 모델들을 학습시키다보면 필연적으로 train set과 test set을 나눠야 하는 일이 발생합니다. 한 번만 나누는 경우는 sklearn에서 제공하는 train_test_split함수를 사용하기도 하지만 많은 경우 cross validation이 가능한 Kfold를 사용합니다. KFold의 방법인 sklearn의 KFold, StratifiedKFold, Repeated, GroupKFold의 차이점을 알아봅니다.
사용할 데이터프레임을 생성합니다.
import pandas as pd import numpy as np target = np.ones(25) target[-5:] = 0 df = pd.DataFrame({'col_a':np.random.random(25), 'target':target}) df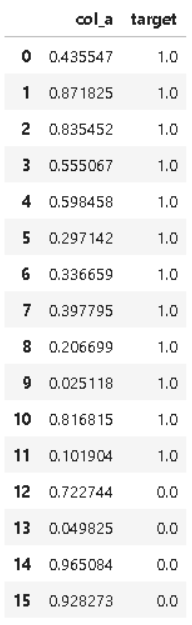
label이 1인 데이터가 12개, 0인 데이터가 4개로 imbalanced한 형태를 띄고 있는 데이터셋입니다. 이 데이터를 학습해야 한다고 가정합시다.
Kfold
from sklearn.model_selection import KFold, StratifiedKFold X = df.col_a y = df.target kf = KFold(n_splits=4) for train_index, test_index in kf.split(X): print("TRAIN:", train_index, "TEST:", test_index)
제대로 모델을 학습시키기 위해서는 매 split마다 0과 1이 train set과 test set에 고루 분포가 되어있어야 할 것입니다. 하지만 확인을 해보면 4번째로 나눈 train, test set의 경우, label = 0인 인덱스가 전부 test set으로 분류가 되어 있는 것을 확인할 수 있습니다. 왜냐하면 KFold함수는 label의 imbalanced와 상관없이 정량적으로 데이터를 나누기 때문입니다.
StratifiedKFold
skf = StratifiedKFold(n_splits=4) for train_index, test_index in skf.split(X, y): print("TRAIN:", train_index, "TEST:", test_index)
StratifiedKfold의 경우, label의 비율에 맞게 train set 과 test set을 분류합니다.
RepeatedKFold, RepeatedStratifiedKFold
위에서 언급했던 KFod, StratifiedKFold를 Repeat(반복)해서 수행합니다. 그렇기 때문에 몇 회 반복할 것인지(n_repeat)를 인자로 주어야 하며, 자동으로 Shuffling기능이 활성화되어 있습니다.
from sklearn.model_selection import RepeatedKFold, RepeatedStratifiedKFold, GroupKFold X = df.col_a y = df.target kf = RepeatedKFold(n_splits=4, n_repeats=4) for train_index, test_index in kf.split(X): print("TRAIN:", train_index, "TEST:", test_index)
4번 반복하기 때문에 총 16번의 KFold가 수행되었습니다. RepeatedStratifiedKFold의 경우는 StratifiedKFold를 반복해서 실행합니다.
GroupKFold
GroupKFold의 경우, 그룹으로 지정된 데이터들을 하나로 묶여서 split할 수 있는 KFold방법입니다. 예를들어, 사람들의 얼굴을 인식하는 모델의 경우 A라는 사람의 얼굴이 10장있을 때, 이 얼굴은 train set과 test set으로 나뉘지 않는 것이 모델의 성능을 평가하기에 좋습니다. 왜냐하면 train set에서 학습되었던 A라는 사람의 얼굴이 test set에 들어가 있는 경우 정확한 모델의 성능을 측정하기 어렵기 때문입니다.
from sklearn.model_selection import RepeatedKFold, RepeatedStratifiedKFold, GroupKFold X = df.col_a y = df.target groups = np.array([0,0,0,0,0,1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4]) group_kfold = GroupKFold(n_splits=2) group_kfold.get_n_splits(X, y, groups=groups) for train_index, test_index in group_kfold.split(X,y,groups): print("TRAIN:", train_index, "TEST:", test_index)위의 코드는 데이터를 순차적으로 5개씩 묶어 그룹으로 지정한 경우입니다. 주의해야 할 점은, 모든 데이터 value들을 그룹으로 지정해주지 않으면 에러가 난다는 점입니다.
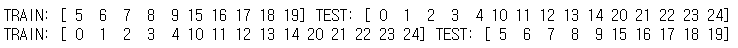
데이터들이 그룹으로 묶여있기 때문에 train set과 test set으로 분리되지 않는 것을 확인할 수 있습니다.